最近「Google文件」推出了一個新的功能,只要我們在上傳PDF文件檔或圖片時,若勾選「 將 PDF 檔案或圖片檔案中的文字轉換為Google 文件」功能的話,在上傳之後,會自動將PDF或圖片中可以辨識的文字擷取出來,並記錄在Google文件中讓我們進一步做編輯。
初步測試,以軟體編製的PDF文件中的文字可以正常抓得到,,
網站名稱:Google 文件(Google Docs) 網站網址:http://docs.google.com
使用方法:
第1步 開啟並登入Google Docs網站,按一下左上角的「上傳」按鈕。
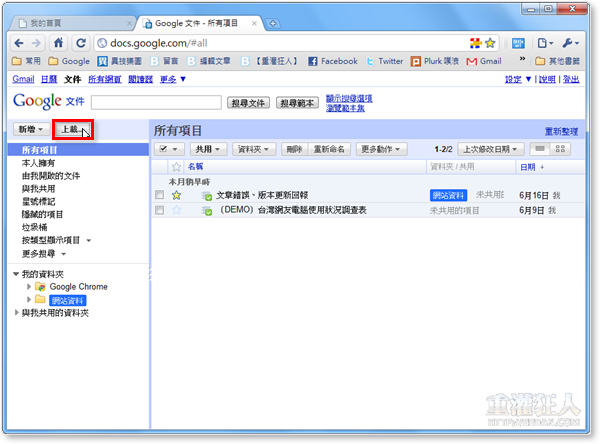
第2步 先按「請選取要上載的檔案」選取你要上傳的PDF文件檔,然後勾選「將 PDF 檔案或圖片檔案中的文字轉換為Google 文件」這個項目,再按一下「開始上載」,將PDF文件檔上傳到Google Docs網站去。
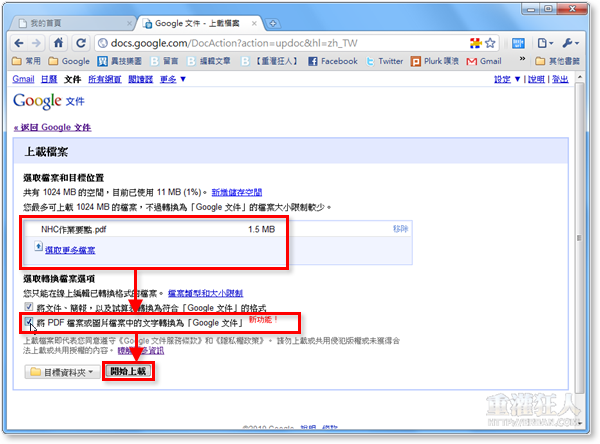
第3步 上傳完成後,按一下檔案名稱,開啟文件內容。
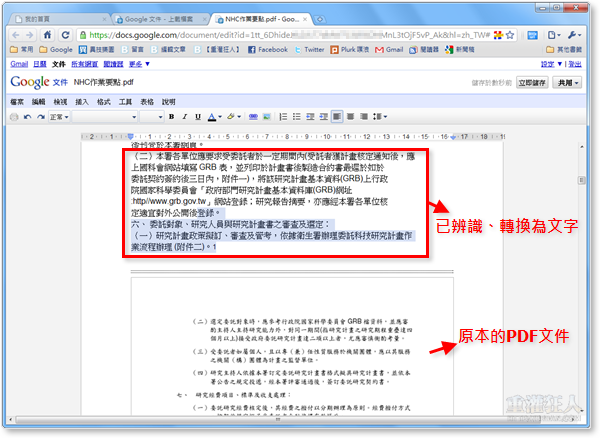
第4步 如圖,原本儲存在PDF文件中的文字內容已經被擷取出來,並儲存在Google Docs文件中讓我們編輯了。
文字上方還會以圖示的方式附上原本的PDF文件內容,讓我們比對看看有沒錯漏。 基本上文字方面的辨識能力還算可以,不過轉換後的排版與版面配置、表格的部份就沒法強求了。
,延伸閱讀: